زبان Extensible Markup Language یا زبان نشانه گذاری قابل توسعه که به اختصار به آن XML میگویند، یک زبان متنی برای انتقال اطلاعات به صورت تگ های مشخص است. بسیاری از دیتابیس ها برای ورود اطلاعات به پایگاه خود از این فرمت استفاده میکنند. مثلا پایگاه PubMed برای بخش PubMed central یا همان PMC که مقالات علمی پزشکی نشریات منتخب را به صورت متن کامل منتشر میکند از نشریات میخواهد که اطلاعات مربوط به مقالات خود را تحت فرمت XML به این پایگاه داده ای وارد کند، سپس مقالات به این شکل در این سایت نمایش داده میشود.
برای ورود اطلاعات مقالات به کراس رف نیز شما بایستی برای مقالات فایل XML تهیه کنید. فایل های نمونه مختلف برای سورس های مختلف مثل مقاله چاپ شده در یک نشریه، کتاب، همایش و … در سایت کراس رف در بخش XML Examples موجود است. ولی ساخت فایل XML برای هر مقاله آن هم به صورت دستی کار بسیار سخت و پر اشتباهی است، چون اطلاعات هر مقاله به صدها یا هزاران تگ تبدیل میشود.
اما جای نگرانی نیست. بسیاری از CMSهایی که سرویس مدیریت آنلاین نشریات را ارائه میدهند، برای گرفتن خروجی مناسب کراس رف در سایت خود امکاناتی دارند. شرکت یکتاوب که نرم افزار یکتاوب را برای مدیریت نشریات و همایش ها در کشور ارائه میدهد، مسیر خوبی برای دسترسی به XML کراس رف در سایت خود دارد که در بخش مدیریت میتوان به آن دست یافت. اما سیناوب که دیگر مجموعه ایرانی ارائه دهنده نرم افزار مدیریت نشریات علمی است، برای دریافت فایل XML برای هر ایشو مسیر مجزایی تعریف نکرده و بایستی به روشی خاص این XML را از سایت استخراج نمود. برای آشنایی با نحوه دریافت فایل XMLکراس رف در سایت های سیناوب این فایل را ملاحظه کنید.
همچنین اگر مجله شما از نرم افزار OJS PKP برای مدیریت آنلاین نشریه خود استفاده میکند نیز میتوانید با بهره گیری از یک پلاگین، از شماره های خود فایل XMLکراس رف تهیه کنید. همانطور که میدانید OJS یا Open Journal System یک نرم افزار رایگان و متن باز (Open Source) است که میتوانید با نصب آن روی هاست خود، یک سایت اختصاصی برای مدیریت نشریات علمی داشته باشید. بسیاری از مجلات مستقل در دنیا، حتی نشریات بزرگ، از نرم افزار OJS برای مدیریت آنلاین مجله علمی خود بهره میبرند. تمامی قابلیت هایی که یک نرم افزار برای مدیریت یک مجله علمی نیاز دارد در طی سالیان توسط افراد مختلف به این مجموعه اضافه شده و یک پکیج کامل را برای مدیریت آنلاین یک نشریه علمی را گردآوری شده است. اگر از OJS استفاده میکنید برای آگاهی از نحوه گرفتن خروجی XMLکراس رف این فایل را مطالعه کنید.
ویرایش فایل XML کراس رف
حال که با XMLکراس رف و خروجی گرفتن این فایل از سایت های مختلف آشنا شدید، نیاز است که این فایل های را باز کرده و بازبینی کنیم. همانطور که قبلا گفته شد، فایل های XML متنی هستند و شما میتوانید با یک نرم افزار ویرایشگر متن یا Text Editor این فایل را مشاهده و ویرایش کنید. پیشنهاد ما نرم افزار متن باز ++NotePad است که میتوانید از اینجا دانلود کنید. اما برای اینکه بتوانیم مشکلات فایل XML را شناسایی و برطرف کنیم نیاز به چیزی بیشتر از یک ویرایشگر متن داریم. در اینجا نرم افزارهای ویرایشگرXML به کار می آیند که پیشنهاد ما نرم افزار بسیار قدرتمند Oxygen XML Editor است. اما مشکلی که وجود دارد این است که نرم افزار رایگان نیست، اما مانند بسیاری از نرم افزارهای دیگر از جمله همین ویندوزی که در آن مشغول نگارش این متن هستم، نسخه کرک شده آن در وبسایت های داخلی موجود است که پیشنهاد ما دانلود از اینجاست. بعد از نصب برای کرک کردن نرم افزار حتما بخش مربوط به آموزش کرک کردن را مشاهده کنید.
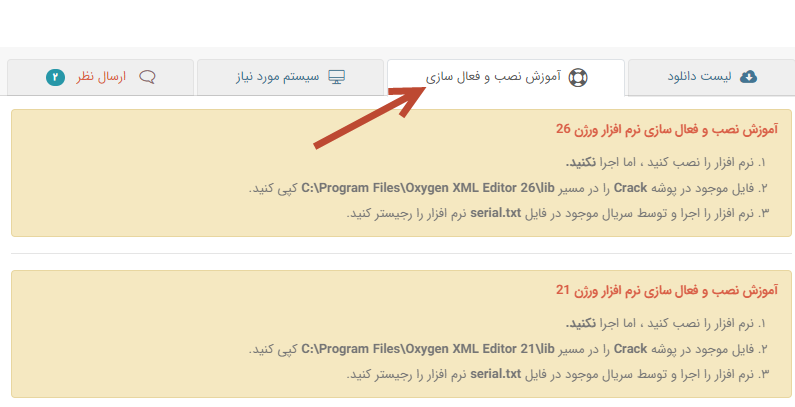
بعد از نصب کردن نرم افزار، فایل XML را توسط این فایل باز کنید. پنجره Outline به صورت پیشفرض باز است، اما اگر نبود از مسیر نشان داده شده در شکل زیر آن را فعال کنید. پنجره Outline به درک راحت تر اجزای مختلف یک فایل XML کمک بسیار زیادی میکند.
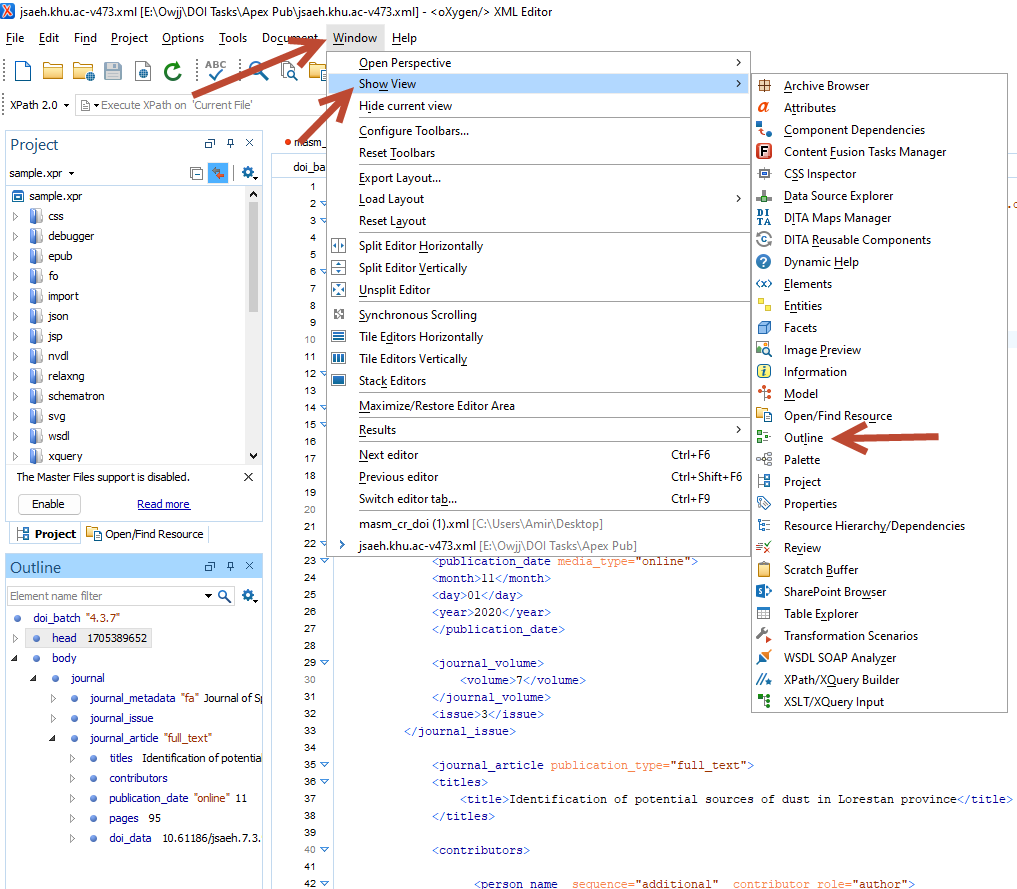
حالا فایل XMLکراس رف موردنظر خود را با نرم افزار Oxygen باز کنید. اگر تگ ها همه پشت هم آمده بودند یا فقط در یک خط بودند، با زدن دکمه زیر میتوانید چیدمان تگ ها را مرتب کنید:
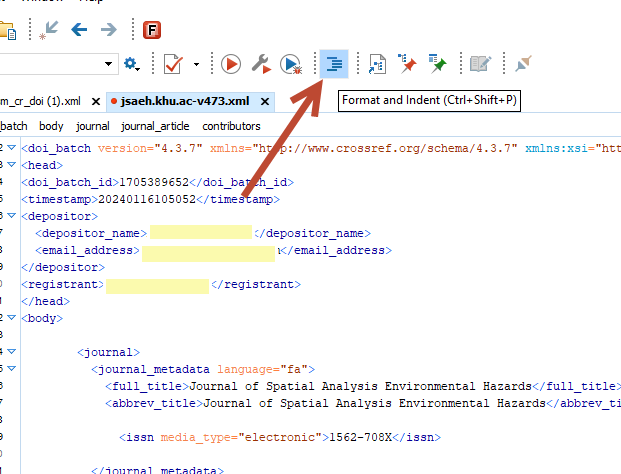
حالا در سمت چپ قسمت Outline را ببینید، روی فلش های کوچک کلیک کنید تا اجزای مختلف باز شود و هر جزء را ببینید. همانطور که مشخص است، یک فایل XML کراس رف برای یک مقاله شامل head و body است. بخش head اطلاعات ناشر را در خود دارد، اما بخش body شامل اطلاعات نشریه و مقاله است. همانطور که در تصویر زیر مشاهده میکنید، بخش Body شامل سه بخش journal_metadata و journal_issue و journal_article است. در بخش journal metadata اطلاعات اصلی نشریه شامل عنوان کامل، عنوان مخفف و شماره شاپا یا همان ISSN است. بخش بعدی یعنی journal issue همانطور که از نامش پیداست حاوی اطلاعات دوره و شماره به همراه تاریخ میلادی آنهاست.
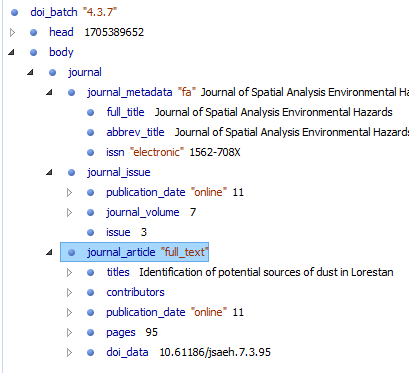
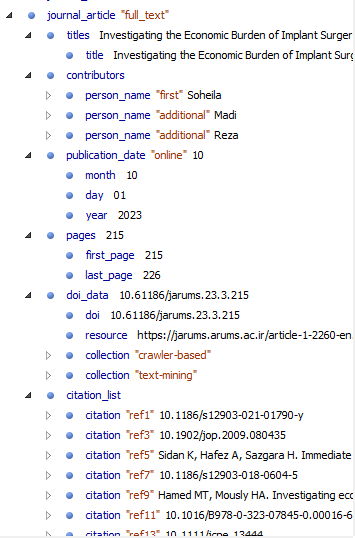
اما بخش journal article که شامل اطلاعات مقاله است خود شامل چندین بخش دیگر است که شامل
- titles: که عنوان یا عناوین مقاله به انگلیسی و اگر زبانهای دیگری دارد، عنوان به آن زبانها نیز در این بخش میآید.
- contributors: که اسامی نویسندگان، وابستگی سازمانی یا افلیشن و کد ارکید نویسندگان در این قسمت قرار میگیرد.
- publication_date: که شامل تاریخ انتشار مقاله است.
- pages: که شماره صفحه ابتدایی و انتهایی مقاله در آن قرار میگیرد.
- doi_data: در این بخش کد doi که میخواهیم به مقاله اختصاص دهیم با رعایت همه ضوابط مربوط به پیشوند و پسوند (prefix and suffix) به همراه لینکی که مقاله در آن نمایش داده میشود، لینکی که برای موتور جستجوی برای این مقاله استفاده میشود و همچنین لینک دسترسی به فول تکست مقاله در این قسمت قرار میگیرد. لینک فول تکست یا متن کامل مقاله از اینجا در اختیار iThenticate هم قرار میگیرد تا متن مقاله از سرقت ادبی مصون بماند.
- citation_list: این قسمت آخرین بخش است و شامل منابع است. کراس رف از این قسمت برای سرویس Linking References استفاده میکند و بین کد DOI آن مقاله و کدهای DOI مقالاتی که در بخش منابع درج شده اند یک رابطه زنجیروار ایجاد میکند که برای دسترسی به اطلاعات علم سنجی و رسم درخت واره ها علمی بسیار موثر است. همچنین باعث افزایش ضریب h-index محقق شده و درجه تاثیر مقاله را نیز بسیار بالاتر میبرد.
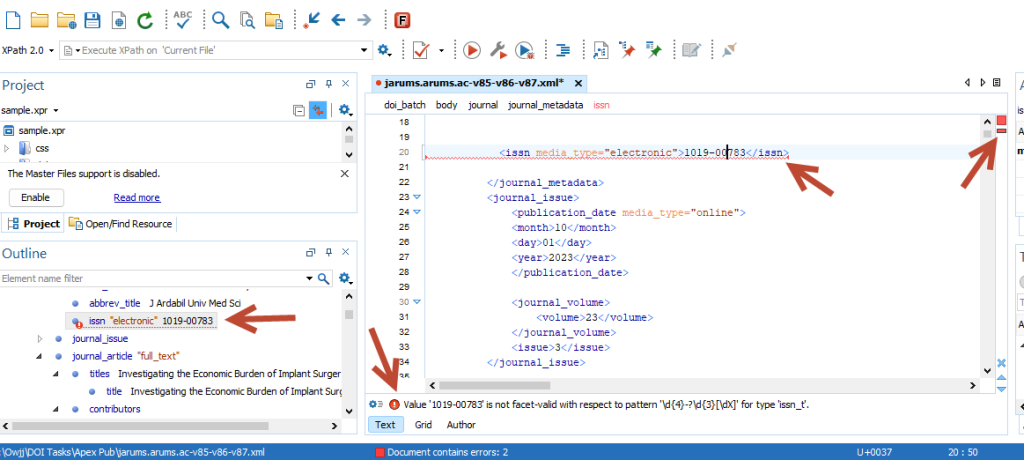
دلیل انتخاب نرم افزار Oxygen برای ویرایش فایل های XML توانایی این نرم افزار در خطایابی فایل های XML است. به این صورت که استانداردهای مدنظر کراس رف در ابتدای فایل در یک لینک آمده است، حال اگر هر کدام از این پارامترها اشتباه وارد شده باشد یا اگر در زمان ویرایش تگ ها را خراب کنیم، نرم افزار با یک ارور قرمز رنگ به ما اطلاع میدهد. مثلا بکس شماره شاپا یا ISSN اگر شماره ای دیگری به جز ISSN در آن وارد شود، ارور زیر را میدهد:
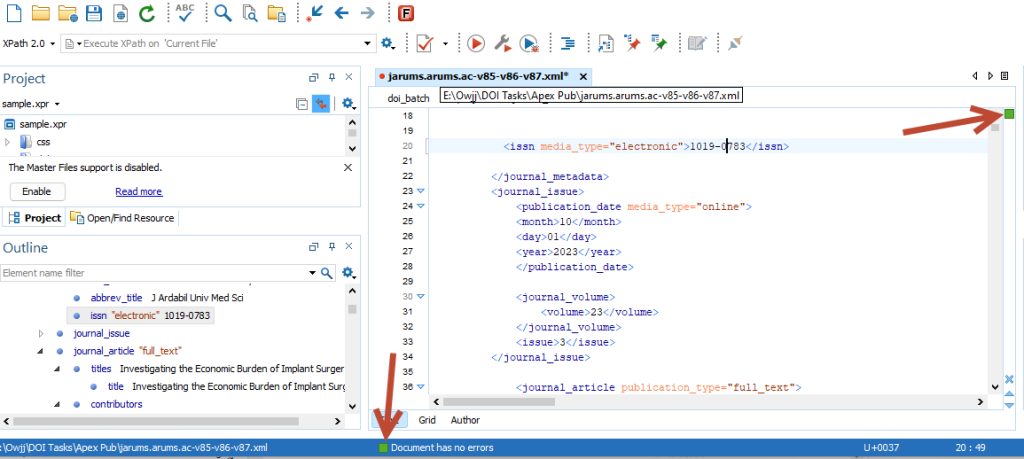
ولی اگر همه چیز اوکی باشد، یک علامت سبزرنگ در گوشه راست بالا نمایش داده میشود.
بسیار عالی